论文题目:基于测小批量预测修正的自监督说话人验证
单位:1.新疆大学计算机科学与技术学院 2.清华大学电子工程系
研究背景
目前高性能的深度学习模型大多通过精心标记的数据集进行训练,随着数据需求量的增加以及人们对数据隐私的重视,基于无标签或少标签的训练方法可以更有效地利用容易收集的无标签数据。2阶段地自监督说话人验证系统通常具有更好的性能,并且聚类-迭代的第二阶段通常决定了性能的上限。通过聚类得到的伪标签中通常包含大量的噪声标签,这将对编码器的迭代更新产生负面影响,因此处理这些噪声伪标签成为了提升自监督说话人系统的关键。
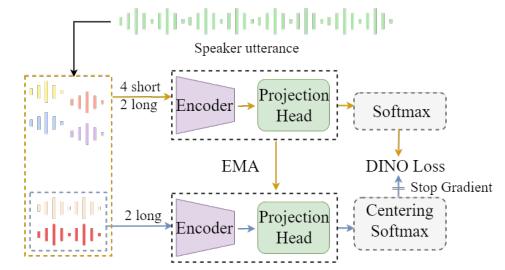
本文在第1阶段使用DINO(self-DIstillation with NO labels)自监督学习框架。该框架通过孪生模型(Siamese model)和自我蒸馏的自监督任务设置,使得编码器具有一定的嵌入提取能力。我们使用ECAPA-TDNN作为编码器(主干网络),在Voxceleb2上训练,并在Voxceleb-O取得了EER 3.49,minDCF 0.375测试结果。
在第2阶段中本文提出了新的迭代方式,在一个迭代(iteration)中使用固定的训练轮次(epoch)并在首个轮次冻结编码器参数,只对分类器进行更新,这可以有效解决由重新聚类导致的伪标签不匹配问题;在剩余的轮次使用我们提出的小批量预测更新方法,该方法分为两个步骤:区分可信伪标签和处理不可信伪标签。
本文沿用DLG的方法,使用包含两个组件的高斯混合模型对上个轮次的训练整体loss分布进行拟合,以两个组件分布的交点值作为当前轮次区分标签可信程度的标准,以实现动态的阈值更新。
2.小批量预测修正
对于筛选出的不可信标签,以往的做法是将预测概率出现大于固定值的样本,以其预测标签进行更新。这样的做法无法适应早期训练以及困难样本训练,并且模型的预测输出概率在每个批量的训练都会产生变化。为了缓解困难样本预测输出不平衡问题,本文首先使用均匀对齐(Unified Alignment,UA),将网络的预测输出概率向更均匀的分布对齐:
![图片[2]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](http://127.0.0.1:81/wx/%E8%AF%AD%E9%9F%B3%E4%B9%8B%E5%AE%B6/images/2024-07-12_ff478a8b1cfbdc774d0ad1cdee973867_1.png)
其中等式右侧分母部分是反应整个训练过程预测的平均水平,但是等待所有样本计算结束再反向传播将会消耗大量的计算资源,因此本文使用指数移动平均方法近似计算:
![图片[3]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](http://127.0.0.1:81/wx/%E8%AF%AD%E9%9F%B3%E4%B9%8B%E5%AE%B6/images/2024-07-12_11a668322742067742733b2b115a8e89_2.png)
其中t=0时的初始情况取1/C。批量内判定修正样本的阈值也使用类似的方式进行更新:
![图片[4]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](http://127.0.0.1:81/wx/%E8%AF%AD%E9%9F%B3%E4%B9%8B%E5%AE%B6/images/2024-07-12_0431ef17926be24ebb21e4ad13ce2177_3.png)
对于第1阶段,数据增强是自监督学习中产生不同样本的关键手段。在Voxceleb1上,我们对比了不同的数据增强方法对DINO的影响,并在Voxceleb-O上进行测试。
表1 不同数据增强方法对DINO框架的影响(Voxceleb1)
如表1所示,频谱增强并不能带来性能的提升,这与监督学习中的结果完全相反;最有效的数据增强方法是加性噪声和混响噪声的随机添加方法。我们在Voxceleb2上进行了训练,相比于其他基于DINO的改良方法,我们的方法在不引入额外方法的情况下取得了和最先进方法相似的性能,结果如表2所示。
表2 和其他第1阶段的研究比较(Voxceleb2)
![图片[7]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](http://127.0.0.1:81/wx/%E8%AF%AD%E9%9F%B3%E4%B9%8B%E5%AE%B6/images/2024-07-12_d42f01a23861947e6b0668d4257880f2_6.png)
对于第2阶段,所有的实验均在Voxceleb2上进行.。我们分别进行了第1轮迭代和完整的4轮迭代的对比实验。
表3 不同第2阶段方法在第1次迭代的对比
![图片[8]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](http://127.0.0.1:81/wx/%E8%AF%AD%E9%9F%B3%E4%B9%8B%E5%AE%B6/images/2024-07-12_a223a784302c7a3e873088398127be80_7.png)
如表3所示,在早期训练的第1轮迭代,我们的方法相对于基线具有更好的性能,说明预测修正和动态修正阈值的组合可以更好地适应早期学习,同时使用性能更优的第1阶段模型也会获得性能提升。
如表4所示,我们的方法相比于基线系统实现了较大的提升,并且我们的主干网络使用通道数为512的ECAPA-TDNN,相比于使用1024通道数的LGL(EER 1.66),在节省了2/3参数量的条件下实现了相似的性能。
在第1阶段,我们探索了影响DINO自监督学习框架的关键因素,并使用最佳的增强方法实现了和当前SOTA相似的性能;在第2阶段,我们提出了新的迭代训练策略和基于小批量的标签修正方法,有效地提升了自监督说话人验证任务的性能。更进一步,该方法也可以应用于其他的基于分类的自监督学习任务或噪声标签修正任务。
参考文献
[1]R. Tao, K. A. Lee, R. K. Das, V. Hautam ̈aki, and H. Li, “Self-supervised speaker recognition with loss-gated learning,” in International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6142–6146.
[2]Z. Fang, L. He, H. Ma, X. Guo, and L. Li, “Robust training for speaker verification against noisy labels,” in Proc. INTERSPEECH, 2023, pp. 3192–3196.
[3]B. Han, Z. Chen, and Y. Qian, “Self-supervised speaker verification using dynamic loss-gate and label correction,” in Proc. INTERSPEECH, 2022, pp. 4780–4784.

![图片[1]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_dcabd17e3eec911a4d40d5abdf6ebebd_0.png)
![图片[2]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_ff478a8b1cfbdc774d0ad1cdee973867_1.png)
![图片[3]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_11a668322742067742733b2b115a8e89_2.png)
![图片[4]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_0431ef17926be24ebb21e4ad13ce2177_3.png)
![图片[5]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_77c2eba6152570d95d11ac4716fb18f8_4.png)
![图片[6]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_76a035b5c03cf6b3960127311b4f506f_5.png)
![图片[7]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_d42f01a23861947e6b0668d4257880f2_6.png)
![图片[8]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_a223a784302c7a3e873088398127be80_7.png)
![图片[9]-基于小批量预测修正的自监督说话人验证 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-12_dde70334e5b3c95326190a1236688d62_8.png)
![[本地]GPT-SoVITS模型推理使用教学-AI星球|配音工坊](https://aiaf.cc/wp-content/uploads/2024/08/420164872620240823093402.png)

![[ 双模型]Bert-VITS2|GPT-SOVITS 舌尖上的中国配音 声音配音模型-AI星球|配音工坊](https://aiaf.cc/wp-content/uploads/2024/07/sjszg.jpg)


















请登录后查看评论内容