
0
摘要
1
Introduction
2
FluentEditor: Methodology
本文提出了一种通过考虑声学和韵律一致性来确保语音流畅性的TSE模型–FluentEditor。
2.1
Overall Workflow
![图片[1]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_e7eef0d2ad0ca329020dc0f03ab213a8_0.png)
如图1所示,FluentEditor采用基于掩码预测的扩散网络作为骨干网络,包括一个文本编码器和一个谱图去噪器。谱图去噪器采用去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM),通过固定长度为p(⋅)的马尔可夫链的反向过程逐步去噪一个正态分布变量来学习数据分布。
假设输入音素序列的音素嵌入为X=(X1,…,X|X|),其对应的声学特征序列为Y^=(Y^1,…,Y^|Y^|)。通过根据概率λ将Y^的随机区间替换为随机向量,可以得到掩码后的声学特征序列Y^mask=Mask(Y^,λ)。具体来说,文本编码器旨在为X提取高层次的语言特征HX。然后,谱图去噪器聚合HX和条件输入C,以指导扩散模型Θ(Yt|t,C)的反向过程(t∈T),其中Yt是干净输入Y^0的噪声版本。类似于[5],条件输入C包括帧级语言特征HfX、声学特征序列Y^、掩码后的声学特征序列Y^mask、说话人嵌入espk和音调嵌入epitcℎ。在基于生成器的扩散模型中,pθ(Y0|Yt)是神经网络fθ(Yt,t)施加的隐式分布,给定Yt输出Y0。然后,使用后验分布q(Yt−1|Yt,Y0)在给定Yt和预测的Y0的情况下采样Yt−1。
为了建模语音流畅性,在原始重建损失的基础上设计了声学一致性损失LAC和韵律一致性损失LPC,以确保编辑区域生成的语音的声学和韵律性能与上下文和原始话语一致。对于重建损失,本文遵循[5]采用平均绝对误差(Mean Absolute Error, MAE)和结构相似性指数(Structural Similarity Index, SSIM)[13]损失来计算Y0与对应的真实片段Y^0之间的差异。声学一致性损失LAC和韵律一致性损失LPC的目的是确保编辑语音区域与相邻声学片段之间的连接点的平滑性,以及掩码语音的局部韵律与真实语音的全局韵律一致。
2.2
Fluency-Aware Training criterion
2.2.1
Acoustic Consistency Loss
拼接代价(Concatenation Loss)是单位选择式语音合成(Unit-selection Text-to-Speech, TTS)中的两个重要训练准则[9,14,15]。其中,目标损失(Target Loss)用于计算候选单位与目标之间的接近程度[15],而拼接代价(Concatenation Loss)[9] 用于计算待连接语音单元的连接平滑度。受到拼接代价[9]的启发,本文提出了声学一致性损失来量化编辑区域与相邻上下文之间的平滑过渡。
声学一致性损失LAC在预测的声学特征Y0的左右边界都采用了平滑度约束。将左右边界的欧氏距离ΔρLY0和ΔρRY0与相应边界处的地面真实语音Δρ^L/RY^0的欧氏距离进行比较,以作为整体平滑度LAC的近似指标。
具体而言,LAC包括LLAC和LRAC两部分,使用均方误差(Mean Squared Error, MSE)[16]来衡量预测片段与地面真实片段之间的接近程度:
![图片[2]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_9919ff5594686dfcc8573d3452022b49_1.png)
值得注意的是两个相邻帧之间的欧氏距离是通过平滑度提取器获得的。以ΔρLY0为例,
![图片[3]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_fce05ccd7d4f6572b15bf706e53eec7d_2.png)
其中,YLpre0表示掩码区域左边界之前的语音帧。换句话说,相邻非掩码区域的结束帧在左侧。方差被用作数据离散度的统计度量,以描述声学特征值的变化[17]。较小的方差可能表明两个频谱之间的相似性较大,而较大的方差可能表明它们之间的差异较大。为了全面捕获音频信号的统计特性,利用方差来表征每个梅尔频谱帧的特征信息,记为ρLY0和ρLpreY0。
类似地,计算右边界的平滑度约束LRAC,其中YRnex0表示掩码区域右边界之后的语音帧,换句话说,相邻非掩码区域的开始帧在右侧。
2.2.2
Acoustic Consistency Loss
韵律一致性损失LPC负责从预测的掩码区域Y0中提取韵律特征HPY0,同时分析原始语音中存在的整体韵律特征H^PY^,然后采用均方误差(MSE)损失来进行韵律一致性约束。
![图片[4]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_49751580dd91a3d579874c23e5736f16_3.png)
请注意,韵律特征HPY0和H^Y^P是由预先训练的韵律提取器获得的。具体来说,局部韵律提取器和全局韵律提取器都使用了全局风格标记(GST)模型[11]中的参考编码器[11],将Y0和Y^转换为具有固定长度的高级韵律向量,以便进行简单的比较。
![图片[5]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_e6dccee74216b0f7661f3d98fbdfa438_4.png)
最后,按照[5]的做法,总损失函数是重建损失和两个新的损失函数LAC和LPC在所有非连续的掩码区域上的总和,因为一个句子中的掩码区域可能包括多个非连续的段[5]。简而言之,FluentEditor的LAC和LPC被引入以确保具有一致韵律的流畅语音。
2.3
Run-time Inference
在运行时,给定原始文本及其语音,用户可以通过编辑文本来编辑语音。需要注意的是,我们可以手动定义修改操作(即插入、替换和删除)。给定文本中编辑单词的相应语音片段被视为图1中的掩码区域。与[5]类似,FluentEditor读取编辑后的文本以及原始语音的剩余声学特征Y^−Y^mask来预测编辑单词的Y0。最后,Y0及其上下文Y^−Y^mask被连接成最终的流畅输出语音。
3
Experiments and Results
3.1
Dataset
本文采用VCTK \cite{veaux2017cstr} 数据集验证FluentEditor模型,这是一个由110名具有各种口音的英语发音者发音的英语语音语料库。每个录音采样频率为22050 Hz,量化为16位。通过Montreal Forced Aligner (MFA) [18]实现了精确的强制对齐。本文将数据集随机划分为训练集、验证集和测试集,比例分别为98%、1%和1%。
3.2
Experimental Setup
文本编码器和频谱去噪器的配置参考了[5]。FluentEditor系统的扩散步数T设置为8。按照GST [11]的方法,韵律提取器包括一个卷积堆栈和一个RNN。基于GST的韵律提取器的输出韵律特征的维度为256。本文根据[3]采用随机选择策略,以固定的80%掩码率掩盖特定音素跨度及其对应的语音帧。预训练的HiFiGAN [19]声码器用于合成语音波形。批次大小设置为16,初始学习率设置为2×10^−4,并使用Adam优化器[20]来优化网络。FluentEditor模型在一张A100 GPU上训练了200万步。
3.3
Evaluation Metric
为了主观评价,本文进行平均意见评分(Mean Opinion Score, MOS)[21]听觉评估,以语音流畅度为指标,称为FMOS。需要注意的是,FMOS允许听众感受到编辑后的语音片段相对于上下文是否流畅。并在不同模型之间保持文本内容和文本修改的一致性,以排除其他干扰因素,仅检验语音流畅度。此外,还使用了比较FMOS(C-FMOS)[21]进行消融研究。在客观评价方面,利用MCD [22]、STOI [23]和PESQ [24]来衡量编辑语音的整体质量。
3.4
Comparative Study
本文开发了四个神经网络TSE系统进行比较研究,包括:1)CampNet [2]提出了一个上下文感知的掩码预测网络来模拟基于文本的语音编辑过程;2)A3T [3]提出了对齐感知的声学-文本预训练方法,该方法将音素和部分掩码的频谱图作为输入;3)FluentSpeech [5]将扩散模型作为骨干,并在上下文语音的帮助下预测掩码特征;4)FluentEditor (Ours)设计了声学和韵律一致性损失。本文还添加了Ground Truth语音进行比较。需要注意的是,本文构建了两个消融系统,分别是“w/o LAC”和“w/o LPC”,以验证这两个新损失的有效性。
3.5
Main Results
在本节中,介绍了研究的主要结果,侧重于重构和编辑语音的综合评估,包括客观指标和主观评估的综合分析。
3.5.1
Main Results
![图片[6]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_9c414982fa0cf62533fc3364850f5318_5.png)
Objective results: 从测试集中随机选择400个测试样本,并在表1的第二至第四列中报告客观结果。请注意,本文遵循[5]并仅使用重建的语音测量被掩盖区域的客观指标。FluentEditor在整体语音质量方面取得了最佳性能。例如,FluentEditor的MCD和STOI值获得了最优的结果,而PESQ在所有系统中获得了次优的结果。它表明FluentEditor对要编辑的语音区域进行了正确的声学特征预测。请注意,客观指标不能完全反映人类的感知[25],还需进一步进行主观听力实验。
3.5.2
Evaluation of Edited Speech
Subjective results: 为了进行FMOS评估,我们从测试集中选择了50个音频样本,并邀请了20名听众对语音流利度进行评估。在[26]之后,我们测试插入和替换操作,并在表1的最后两列中展示FMOS结果。FluentEditor始终取得更高的流利性相关感知分数。例如,FluentEditor在插入时获得4.25的FMOS值,在替换时获得4.26的FMOS值,非常接近真实值。这证明了流畅度感知训练标准的有效性。FluentEditor通过考虑声学和韵律一致性约束,削弱了编辑痕迹,提高了编辑语音的韵律性能。
3.6
Ablation Study
![图片[7]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_7a9e126e93647940615bcfea2cabbbdc_6.png)
为了进一步验证LAC和LPC的消融实验,表2报告了插入和替换的主观和客观消融结果。按照上一节的内容准备示例和聆听者。当去除LAC和LPC时,两种消融系统的C-FMOS和MCD值均下降,说明声学和韵律一致性约束对增强编辑后语音的自然度和流畅度都起着至关重要的作用。值得注意的是,韵律一致性在编码和提取语音韵律特征后表现出更显著的预测结果,强调了其在语音编辑韵律流畅性方面的有效性。
3.7
Visualization Analysis
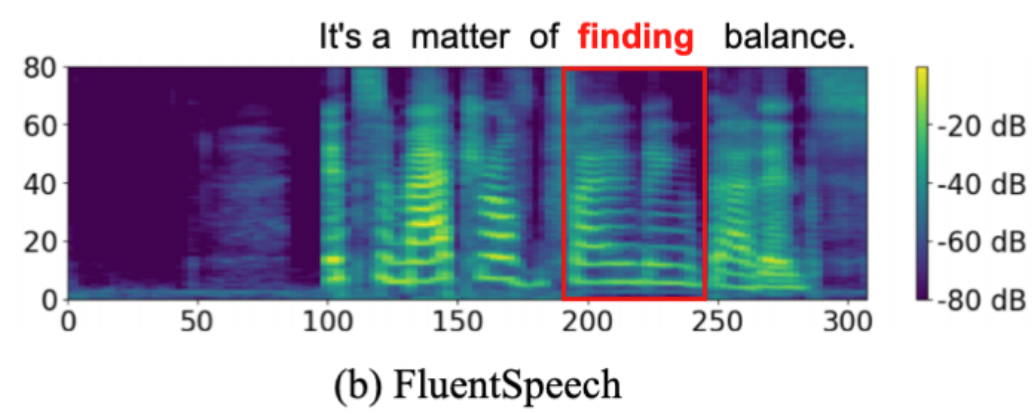
![图片[8]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_08f50daade58c0de05371d2fa4a8c688_7.png)
![图片[9]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_abcda55e9fb3c2081079a42a48479d87_8.png)
![图片[10]-声学和韵律一致性的基于文本的语音编辑 - AI星球|配音工坊-AI星球|配音工坊](../images/2024-07-17_481d4388d057d1ea0745782bfbba5129_9.png)
如图2所示,将FluentEditor产生的梅尔语谱图和流利语音基线\footnote{由于篇幅限制,只报告流畅语音基线。更多可视化结果和语音样本请参考网站:\url{https://anonymous.4open.science/w/FluentEditor-B684/}。}可视化。红框表示随机掩码及其编辑的语音片段”It‘s a matter of finding balance”。可以看到,FluentEditor可以生成比基线更丰富的频率细节的梅尔语谱图,从而产生自然和富有表现力的声音,这进一步证明了声学和韵律一致性损失的有效性。尽管如此,我们还是建议读者听一下我们的语音样本1,更好的感受Fluenteditor的优势。
4
Conclusion
本文提出一种新的基于文本的语音编辑(TSE)模型FluentEditor,涉及两个新的流利度感知训练标准,以改善编辑后语音的声学和韵律一致性。声学一致性损失LAC用于计算边界处的方差是否接近真实拼接点的方差,韵律一致性损失LPC用于让待编辑区域内合成音频的高层韵律特征接近原始语音。通过这种方式,FluentEditor可以在语音流畅性方面提升语音编辑性能。在VCTK数据集上的客观和主观实验结果表明,结合LAC和LPC可以获得更好的效果,并保证语音流畅和韵律一致。在未来的工作中,我们将考虑多层次的一致性,并进一步改进FluentEditor架构。
![[本地]GPT-SoVITS模型推理使用教学-AI星球|配音工坊](https://aiaf.cc/wp-content/uploads/2024/08/420164872620240823093402.png)

![[ 双模型]Bert-VITS2|GPT-SOVITS 舌尖上的中国配音 声音配音模型-AI星球|配音工坊](https://aiaf.cc/wp-content/uploads/2024/07/sjszg.jpg)


















请登录后查看评论内容