个人博客共7篇
排序
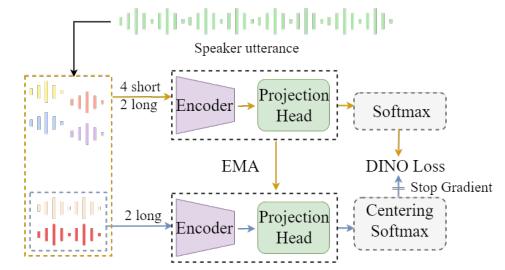
基于小批量预测修正的自监督说话人验证
论文题目:基于测小批量预测修正的自监督说话人验证作者列表:王钧旭,方志华,何亮单位:1.新疆大学计算机科学与技术学院 2.清华大学电子工程系 研究背景目前高性能的深度学习模型大多...
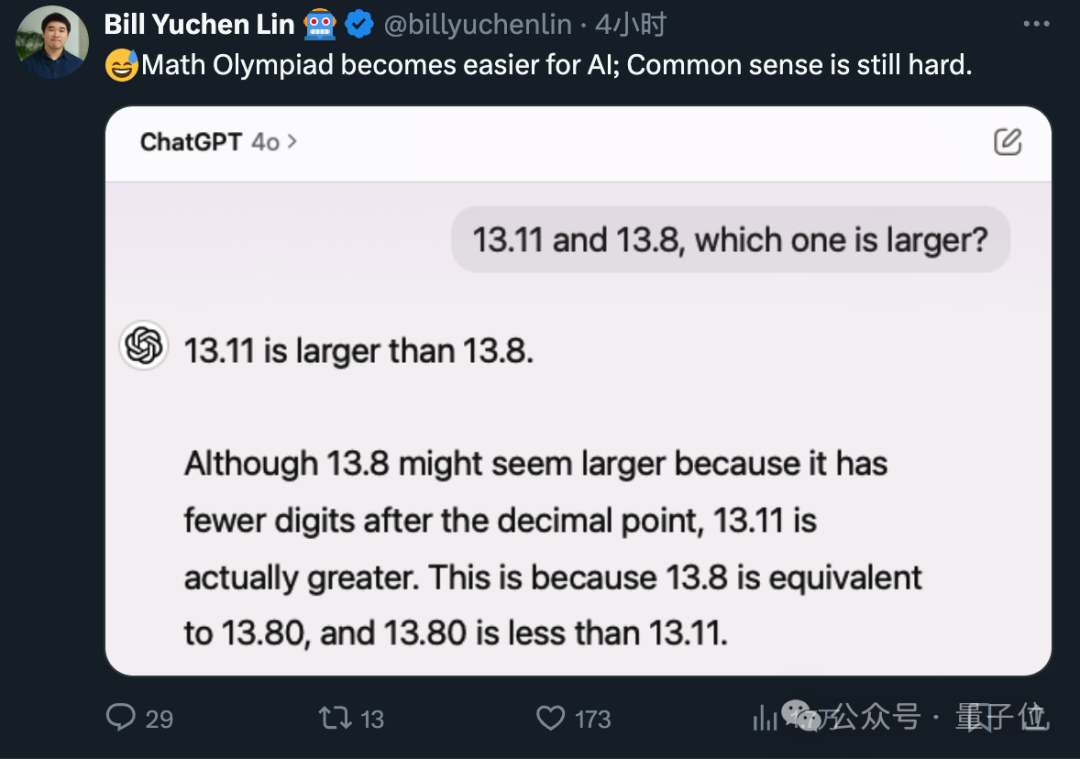
大模型集体失智!9.11和9.9哪个大,几乎全翻车了
没眼看……“9.11和9.9哪个大”这样简单的问题,居然把主流大模型都难倒了??强如GPT-4o,都坚定地认为9.11更大。来源丨量子位谷歌Gemini Advanced付费版,同样的口径。新王Claude 3.5 Sonnet...

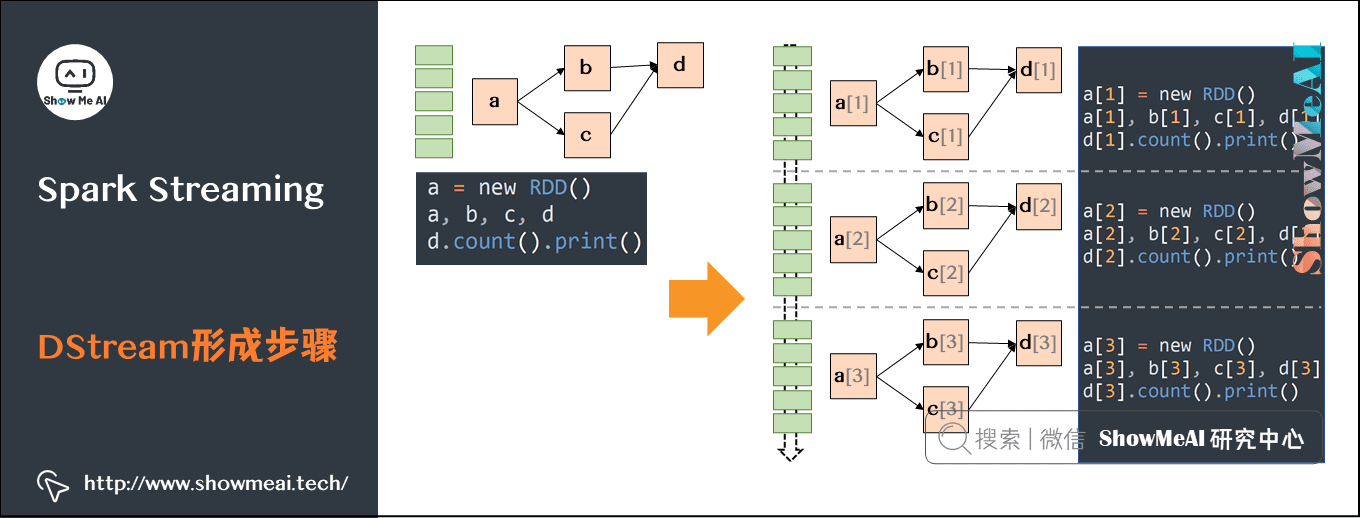
浅谈大模型的多模态和语音流式技术
ChatGPT 引爆LLM的同时scaling law席卷了整个机器学习行业,openai 、meta、google等公司在语音方向也分别推出了whisper、mms、audioPaLM多个语音大模型,在模型和数据规模上再次发挥scaling...
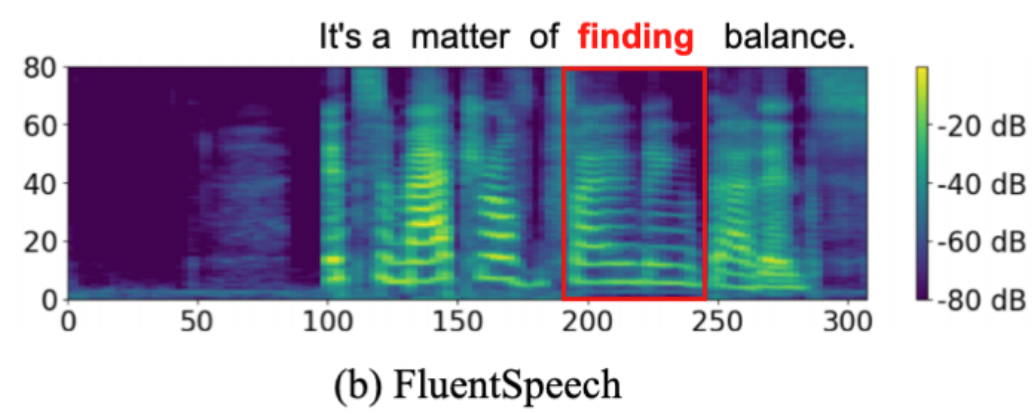
声学和韵律一致性的基于文本的语音编辑
本次分享由内蒙古大学计算机学院S2Lab实验室(https://ttslr.github.io)刘瑞研究员团队投稿在 InterSpeech 2024的论文《FLUENTEDITOR: TEXT-BASED SPEECH EDITING BY CONSIDERINGACOUSTIC AND ...

SD-Eval新基准,让语音交互大模型情智兼备
随着GPT-4o、Moshi等模型的发布,语音交互大模型越来越受到大家的关注。如何全面的评价语音交互大模型的情商?最近港中大(深圳)联合字节跳动提出了SD-Eval,一个多维度评估语音对话理解和生成...
语音合成,流式处理、非流式处理 有什么区别?用途是什么
语音合成技术中的流式处理与非流式处理在多个方面存在显著差异,这些差异主要体现在处理方式、实时性、用户体验以及应用场景上。区别 流式处理非流式处理处理方式分段合成,即边输入边输出,对...

语音/音频处理学术速递
今日论文合集:cs.SD语音7篇,eess.AS音频处理10篇。cs.SD语音【1】 A Preliminary Investigation on Flexible Singing Voice Synthesis Through Decomposed Framework with Inferrable Feat...